
Dette sidste afsnit i EyeJustRead’s viden-om-serie demonstrerer, hvordan udviklingen af automatisk afkodning af enkeltord også sætter sit spor i læserens øjenbevægelser. Serien har fokuseret på, hvordan analyser af øjenbevægelser kan bidrage til læsevejlederes praksis. De tidligere afsnit har beskrevet flydende læsning, og hvordan den afspejles i øjenbevægelser, og hvordan gentaget læsning kan bruges som en model for den enkelte elevs læseudvikling.
Automatisk opfølgning på automatisk afkodning
Automatisk afkodning er en væsentlig ingrediens i funktionel læsning – jo større en del af skriftsproget, der afkodes uden bevidst intention, jo større en gevinst for læseren. Den automatiske afkodning er vigtigere og vigtigere i en skolehverdag med stigende forventning om selvstændig læsning på tværs af fag. Opfølgningen på en elevs evner til at afkode automatisk kan lettest adresseres subjektivt; oplever eleven, forældrene og faglærere at eleven har lettere ved at følge med? Hvor flydende lyder elevens læsning? Denne sidste artikel i serien viser, hvordan EyeJustRead’s forskning og udvikling kan gøre det til en mere objektiv og mindre tidskrævende opgave at vurdere læseres udvikling af automatisk afkodning.
Læsefejl og læsesuccess
En udfordring i læseundervisningen er, at automatiseret afkodning er en uhåndgribelig størrelse at måle pålideligt. For læseren er automatisk afkodning en “ikke-oplevelse”, som netop er kendetegnet ved at foregå automatisk og ubesværet. For læsevejlederen kan det virke helt urealistisk at prioritere at forfølge alle de ord, der ikke tager en elev lang tid at læse. (I forskning kan EEG og andre hjernescanningsmetoder med høj tidsopløsning dog afsløre ordgenkendelse med nogen succes.) En udbredt og velunderbygget praksis i læsevejledning er at registrere læsefejl for at kortlægge, hvilke bogstav-lyd-kombinationer, ord og faste vendinger, eleven ikke genkender og afkoder præcist. Indirekte kan man danne et overblik over elevens formodede fremskridt udfra nedgang i læsefejl. Optælling af fejl siger dog noget om overgangen fra, at en elev lige netop kan afkode et ord med besvær, til at ordet afkodes automatisk. Med udgangspunkt i at hurtigere læsning samlet set er et tegn på mere sikker læsning, kan eye-tracking bruges til automatisk at finde og sammenligne de detaljerede mønstre i øjenbevægelserne, som afslører, hvor det er lykkedes for læseren at forbedre sin læsetid. Det åbner også muligheden for at følge op på, om elevens fremskridt kan ses på tværs af forskellige bøger og over tid. Det giver en helt ny og hidtil uopnåelig mulighed for at tegne et samlet billede af, hvor langt læseren er kommet med at automatisere sin afkodning.
Enkeltord og stavelser læst i forskellige kontekster
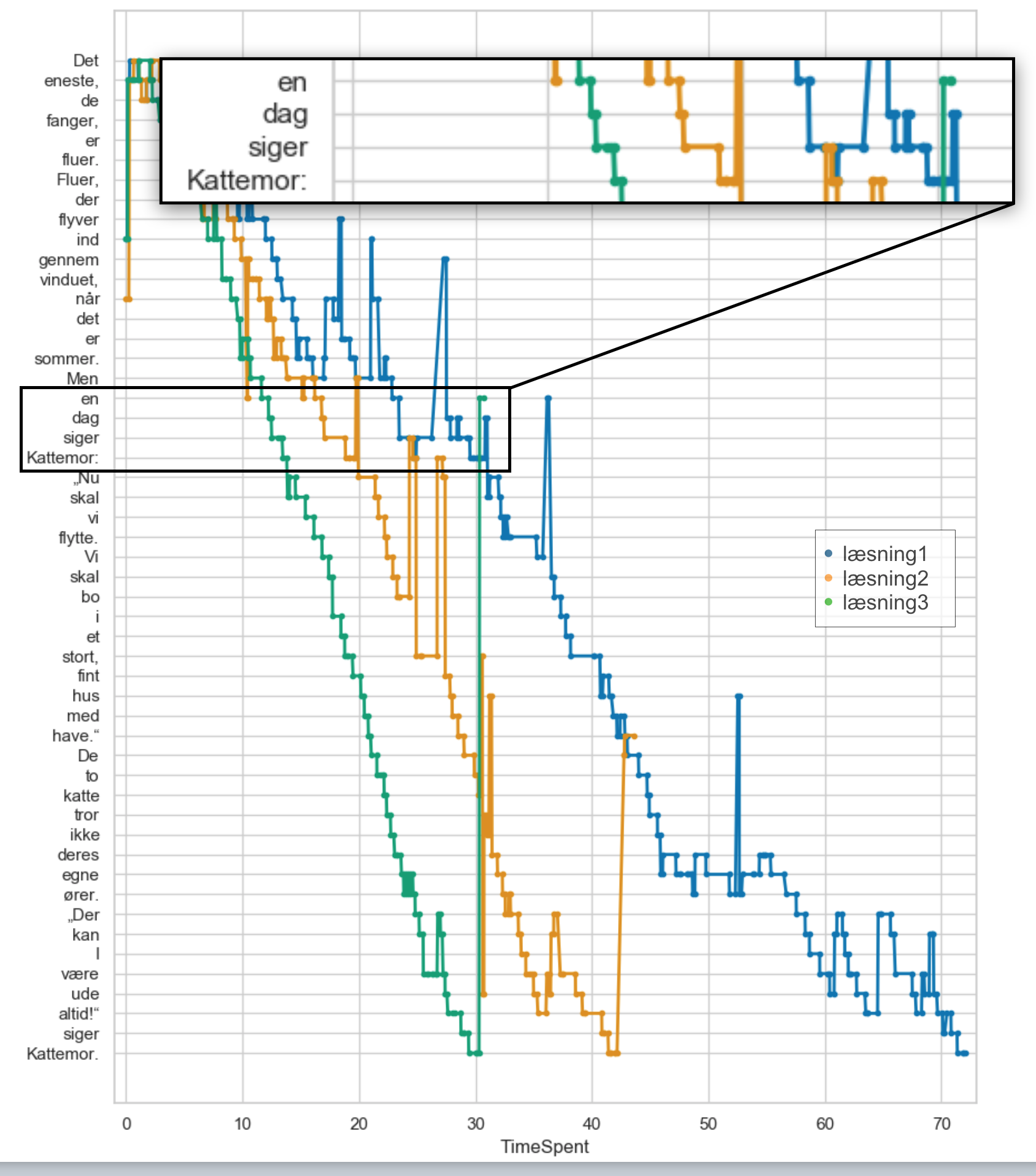
I forrige afsnit af denne serie var fokus på en enkelt elevs gentagne læsninger. De tre læsninger af den samme side er også vist i trappediagrammet herover. Hvis vi starter med at lede efter de konkrete ord, der koster eleven ekstra tid, kan vi fx. se nærmere på ordet ‘siger’. Alene trappediagrammet afslører, at det er et ord, eleven konsistent bruger mere tid på end de foregående ord ‘en dag’. Det ses også, at afkodningen af ordet ‘siger’ fører til en anseelig hastighedsfremgang over de tre genlæsninger. Så for hver læsning bliver ordet genkendt med større sikkerhed. Med udgangspunkt i disse tre læsninger af ordet, fortsætter vi med at følge elevens læsning af ‘siger’ i andre bøger. Afslutningsvis sætter vi fokus på at sammenlignelige ord for at svare på, om læseren ser ud til at genkende og automatisk afkode denne bogstav-lyd-kombination med større sikkerhed.
Enkeltordslæsehastighed
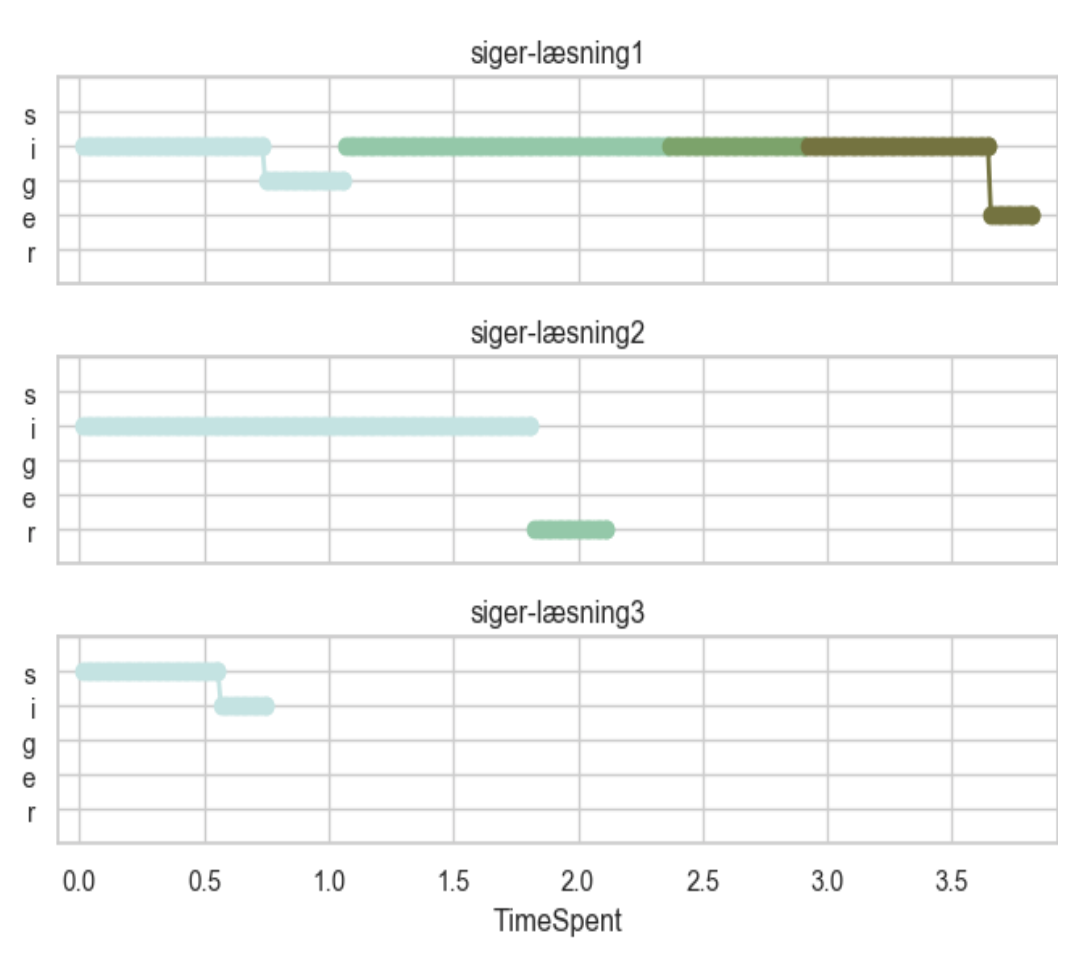
I figuren herover illustreres elevens tre læsning af ‘siger’ fra den første gang, ordet optræder i bogen. Diagrammerne viser den samlede tid, læseren har kigget på ordet. “Brugt tid” er angivet på x-aksen (hver lodret linie svarer til et halvt sekund). Y-aksen, som før havde en streg for hvert ord på siden, har nu i stedet én streg for hvert bogstav i ordet ‘siger’. Grafen skifter farve og bliver mørkere, hver gang eleven har kigget væk fra ordet i kort eller lang tid. En tyk, vandret streg i én farve repræsenterer altså én fiksering det samme sted i ordet. Den længste fiksering finder derfor sted i læsning2 og er næsten to sekunder lang. En tynd, lodret streg viser en saccade inde i ordet, dvs. den hurtige øjenbevægelse når øjet bevæger sig mellem to fikseringer. For at holde figuren tilstrækkelig enkel, er saccader til og fra andre ord, ved hvert af grafernes farveskift, ikke illustreret. De vigtigste konklusioner, der kan læses ud af figuren, er, at den samlede læsetid for ordet ‘siger’ falder fra 3,8 til 0,8 sekunder. Desuden aftager antallet af fikseringer fra 6 til 2, og stort set alle fikseringer er rettet mod første halvdel af ordet. Elevens ordlæsehastighed øges altså markant i løbet af de tre læsninger, og noget tyder på, at endelsen ‘-er’ næppe har fået nogen bevidst opmærksomhed.
Generalisering til andre kontekster
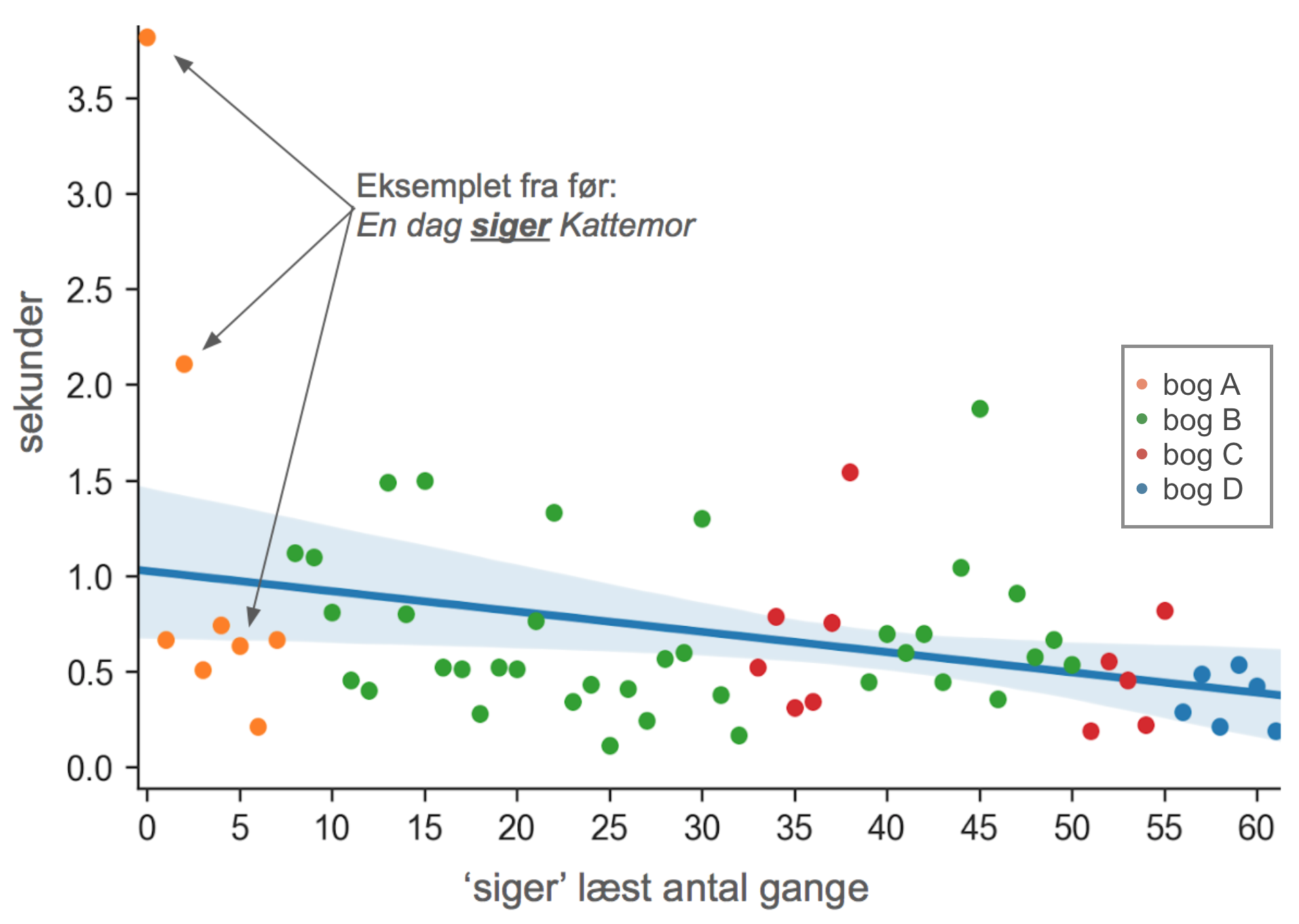
Figuren ovenfor viser elevens udvikling i ordlæsehastighed for alle de steder, eleven har mødt ordet siger. De tre læsninger fra vores tidligere eksemplet er også udpeget, og de andre orange prikker viser øvrige kontekster i den samme bog, hvor der står ‘siger’. De resterende prikker viser andre bøger, hvor ordet ‘siger’ også er blevet læst af eleven.
Den blå linie er en lineær regressionsmodel for udviklingen i læsehastighed baseret på alle 62 datapunkter i figuren. Den statistiske usikkerhed er markeret som en lyseblå skygge. Den lineære regressionsmodel viser, at den forventede ordlæsehastighed for ‘siger’ er halveret fra ca. ét sekund til et halvt i løbet af alle de målte læsninger. Det er klart, at måling af ordlæsehastighed baseret på talrige møder med et ord, med væsentligt større sikkerhed af- eller bekræfter elevens fremgang.
Det er stadig muligt, at eleven i eksemplet har lært at genkende de kontekster, hvor ordet siger findes, uden rigtigt at have lært bogstav-lydforbindelserne i ordet. For nogle ord er det godt nok, og selv meget trænede læsere kan genkende mange låneord på skrift uden nødvendigvis at kende udtalen. Men en læser i Danmark har brug for at kunne afkode de samme bogstav-lyd-par, som i ordet ‘siger’ i mange andre sammensætninger.
Generalisering til andre ord
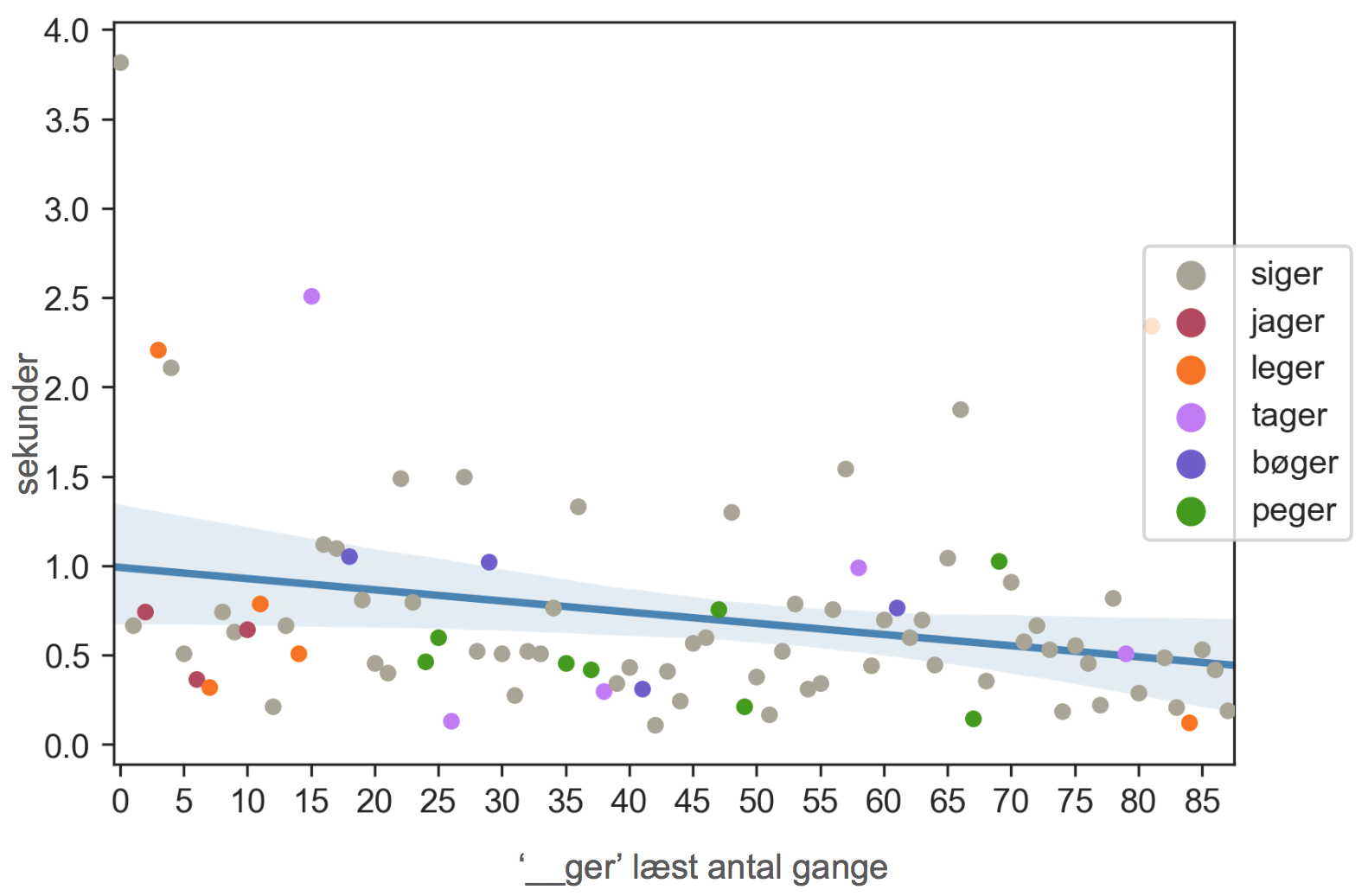
Figuren ovenfor sammenligner flere ord, der har en udtale, som minder om ‘siger’s idet alle ordene starter med en åben stavelse af én konsonant+vokal efterfulgt af stavelsen ‘-ger’. Endvidere udtales sidste stavelse med en j-agtig lyd for g. Eleven har læst fem andre ord, der følger dette mønster i alt 26 gange. De grå prikker er de samme 62 datapunkter for ‘siger’, som indgår i den foregående figur, og hver af de andre farver svarer til et af de fem lignende ord. Den lineære regressionsmodel er beregnet over alle 88 datapunkter og viser en tilsvarende halvering af den forventede ordlæsehastighed. De fem andre ord har tilsyneladende en lignende fremgang i forventet læsehastighed, på trods af at de ikke er blevet læst nær så mange gange. Det giver os endnu større grund til at tro på, at eleven har tilegnet sig endnu en lille bid flydende afkodning, der også kan generaliseres til nye kontekster.
Kan læsevejledere bruge analyser af læseres øjenbevægelser?
De analyser, der er præsenteret i denne artikelserie, giver en stærk indikation af, at eleven i eksemplet er på vej mod automatiseret afkodning af ‘-ger’. Det er en indikation, som en læsevejleder kan tjekke efter, ved fx. at lytte til klip i EyeJustRead med optagede læsninger af ordene i kontekst. Analysen her er sammensat for at vise, at læseres øjenbevægelsesdata gemmer på nogle af de svar, som læsevejledere formentlig ikke forventer at kunne få og bevare overblik over. Det er vigtigt for os, at disse svar formidles til læsevejlederen i en brugbar og overskuelig form, så vejlederen let kan omsætte disse indsigter i sit arbejde med eleven, kollegaer og andre. Desuden samarbejder vi med flere universiteter for at styrke den forskningsbaserede tyngde omkring vores analyser. Det har foreløbig ført til fire videnskabelige publikationer i samarbejde med forskere og studerende ved Københavns Universitet, Danmarks Tekniske Universitet og Copenhagen Business School (ETRA 2018, BEA 2018, SWAET 2018a, SWAET 2018b).
Af Sigrid Klerke, EyeJustRead
Hvis du har kommentarer eller spørgsmål til artiklerne, er du altid meget velkommen til at kontakte Sigrid på sk@eyejustread.com.
Referencer:
ETRA 2018: Klerke, S., Madsen. J.A., Jacobsen, E.J. & Hansen. J.P. (2018). Substantiating reading teachers with scanpaths. I Proceedings of the 2018 ACM Symposium on Eye Tracking Research & Applications (ETRA), s. 85-86. (pdf)
BEA 2018: Bingel, J., Barrett, M. & Klerke, S. (2018). Predicting misreadings from gaze in children with reading difficulties. I Proceedings of the Thirteenth Workshop on Innovative Use of NLP for Building EducationalApplications. s. 24-34. (pdf)(omtale)
SWAET 2018a: Barrett, M., Bingel, J., Klerke,S. & Balling, L.W. (2018): Using naturalistic eye-tracking data to understand children’s reading difficulties. Poster presentation på Scandinavian Workshop on Applied Eye-Tracking 2018. Copenhagen. Abstract to appear in Journal of Eye Movement Research, 11(5). (pdf)
SWAET 2018b: Haffmans, E. & Petersen, S.S. (2018): Reading assessment of children with reading disabilities using scanpaths. Poster presentation på Scandinavian Workshop on Applied Eye-Tracking 2018. Copenhagen. Abstract to appear in Journal of Eye Movement Research, 11(5). (pdf)